
An example of how contract playbooks designed by lawyer experts can be applied to commercial contracts using GenAI.
As the revolution in large language models (LLMs) makes its way into new startups and applications, would-be customers ask: How is my private data protected? Can commercial AI providers use my input data to train their models? The emergence of retrieval augmented generation (RAG), which can inject private data into prompts, has made this an urgent issue, particularly for companies building applications on top of LLMs since they often use those services on behalf of their customers.
The big worry is that intellectual property, trade secrets, other sensitive information, or private information is unknowingly leaked to the public via an LLM’s future output for a different customer. Here is a sample nightmare scenario:
- An HR platform uses a commercial LLM to power its “chat with my performance review” feature. This feature advises end-users, helping them set goals and role-play tough conversations. With one click, enterprise customers can turn on this feature for all employees.
- The HR platform agrees via its contract to let the commercial LLM provider use input and output to “improve the service.”
- The commercial LLM provider then includes end-user inputs in the training set for the LLM’s next training run.
- Future users of the LLM might have access to this sensitive data, regardless of their authorization or what company they work for.
- With a simple query, anyone could prompt the LLM to reveal intimate details about a coworker, friend, politician, or industry influencer’s job performance.
- Chaos ensues.
This may seem unlikely, but it’s technically possible, and we really don’t know the odds. And, of course, a commercial LLM’s terms of service could facilitate it. Those terms could explicitly state that the provider “owns” the service’s inputs and outputs or has broad rights to use them. Of course, any business or consumer software contract could give the provider overbroad rights to customer data. However, only generative AI and other machine learning systems raise this training data concern. Thus, it’s important to understand how any service will use your data.

Fortunately, the major players in the commercial LLM space have done a good job of offering contract terms that protect your inputs and outputs. Many updated their terms during the last couple of months. Our analysis is done by a product called Screens (created by Evan’s team TermScout), which uses GenAI to apply contract review playbooks authored by expert lawyers to the commercial terms of the leading LLMs. For background on Screens, see “TermScout Launches Screens, World’s First Marketplace for Lawyers to Build and Sell Contract Review AIs,” Webwire, Jan 30, 2024.
NB: We ran these contracts through Screens shortly before the publication of this article. Some of these terms have since been updated.
Editor’s note: It is worth comparing this case study to those done by Bill Mooz during the early days of TermScout. See, e.g., Post 236 (examining impact of AI and Big Data on law-risk contract negotiations); Post 292 (examining how in-house innovators were relying upon data to converge on a set of best practices); Post 322 (using data to understand what is market for limitation of vendor liability). All of these examples point in the direction of using data and technology, including AI, to understand and manage legal risk. Remarkably, we are still in the early days. wdh.
Caveats and disclosures
Note that one of us (Evan) is not a lawyer. And while David is, he is not your lawyer. Further, the issues we asked Screens to review may not include your organization’s concerns, in general or for any given contract. Therefore, if you plan to sign one of the contracts we’ve reviewed, you should do your own assessment, ideally with your own lawyer (possibly aided by Screens!). We’re not offering legal advice but rather a report on what Screens found and some analysis based on our experience in the field.
At the outset, it is worth understanding our backgrounds:

Evan is a software engineer and CTO of TermScout. Thus, he signs many terms-of-service agreements with AI service providers and SaaS platforms. He leads TermScout’s SOC 2 compliance program, fills out enterprise information security questionnaires, and talks directly with CISOs of major customers to help them understand how their data is protected on TermScouts’ platform, which uses cloud providers and commercial LLM providers as subprocessors. This has helped him develop opinions on what you should look for in these types of contracts.

David is a lawyer and the founder of Tech Contracts Academy®, which provides training on drafting and negotiating contracts about software, for businesspeople and lawyers (www.TechContracts.com). Those trainings include programs on AI-related contracts. David is also the author of The Tech Contracts Handbook, a popular guide on software agreements published by the ABA. And he’s an expert witness, as well as an occasional instructor at UC Berkeley Law School.
By way of full disclosure—cards on the table—the companies reviewed here include some of David’s legal clients and training customers. But he hasn’t used inside information for this article tailored his views to meet those companies’ needs, or offered any company a chance to review this article in advance.
Finally, one more note of caution: We’ve looked at these companies’ contracts. As a customer, your due diligence should go beyond contracts to the companies’ actual data management, to the extent you can find out about it. This article doesn’t address the latter topic.
TLDR
If you’re just looking for quick answers about these contracts, here you go: The summary review immediately below assumes that you’re a commercial user and that you’re interfacing with these platforms via API, not through a consumer-facing chatbot.
- OpenAI and Anthropic got perfect scores based on the criteria we’re looking at.
- AWS, Google Gemini, and Mistral agree not to use your inputs or outputs to improve their AI services, but they do not explicitly agree to nondisclosure of that data.
- Cohere raises more significant concerns. Their contracts give them broad usage rights to the data you input.
We also look at the Screens’ own Terms and Conditions. While it’s not a commercial LLM provider, Screens is an AI service that handles sensitive data, and we think it has a good contract. Though of course—more cards on the table—Evan’s team drafted it. And David has a business relationship with TermScout (including his own upcoming version of a screen).
The LLM commercial terms being evaluated
Cohere has both a Terms of Use and a Commercial SaaS Agreement. As shown here, customers have to accept both to unlock a production API key, and both seem to govern use of the Cohere API:

For simplicity, we had Screens review the Commercial SaaS Agreement, which is the more customer-friendly of the two agreements. But they have similar terms on use and ownership of customer data.
For Gemini, we had Screens review the Google APIs Terms of Service combined with the Gemini API Additional Terms of Service.
For AWS, we used the AWS Customer Agreement combined with the AWS Service Terms, which contains terms specific to Google’s AI services.
For Mistral, we used the Terms of Use combined with the Terms of service La Plateforme.
Keep in mind that these are publicly hosted standard agreements. If you negotiate with these providers and sign a custom offline agreement, you might get different terms.
Finally, we don’t mean to fire shots. We don’t know why these companies wrote the terms they did—that is, what legal issues and pressures they’re attempting to balance. Actually, we’d love to know, so if you work for one of these companies, don’t hesitate to tell us the reason for your terms, or point out something we misunderstood.
Set-up and methodology
Here’s an simple four-step overview of how we performed this analysis:
Step 1. Evan uploaded these contracts to his private workspace in the Screens platform, which supports various file types, free text input, and URLs (for publicly hosted contracts).

Step 2. Evan created a label and tagged all of the contracts with it. Labels allow you to organize contracts however you might imagine: A set of contracts for a benchmarking analysis (like this), a project for a client, a risk level or deal size, etc

Step 3. Evan imported the AI Service Providers screen from the Screens Community. A “screen” is an AI contract playbook created by an expert to supercharge contract review and negotiation. The screen selected by Evan is designed for buyers or users of any type of AI vendor (foundational model APIs, infrastructure wrappers, vector databases, etc.). It contains seven standards to help users of AI vendors assess the risk involved in using their services.
Step 4. Evan screened all of the uploaded contracts with the AI Service Providers screen.

Results
The above four steps took a few minutes. Now we had our results. Using the bulk analysis feature, we can look at how many of the standards in the screen failed across the set of contracts:

Screens gave us a lot to unpack, so we’ll start with what we think is the most important standard here: the vendor’s usage rights to the data that you input into the service.
1. Input usage rights
Here is how we frame the standard:
The vendor must not receive rights to use inputs to AI services to train their AI models or to share with third parties.
If this standard fails, the vendor may be able to use your data and inputs as training data to further train its AI models. We’ve got a couple non-compliant contracts:

This means that these providers receive some usage rights for customer content, data, or inputs. The nature of their contracts’ non-compliance varies.
Google Gemini explicitly addresses the issue. Their contract gives them broad rights to data submitted to the API, including prompts, images, and documents. Google can use this data to improve machine learning technologies. That’s pretty traditional language for SaaS/cloud providers, so it’s not 100% clear Google wants to use that data for AI training. But the language could give them that right, and they don’t have terms denying such a right. Plus, another clause suggests Google does plan to make very broad use of customer inputs. The contract (in the last paragraph, below) warns you not to “submit sensitive, confidential, or personal information to the Services.”
See below Audit Result:
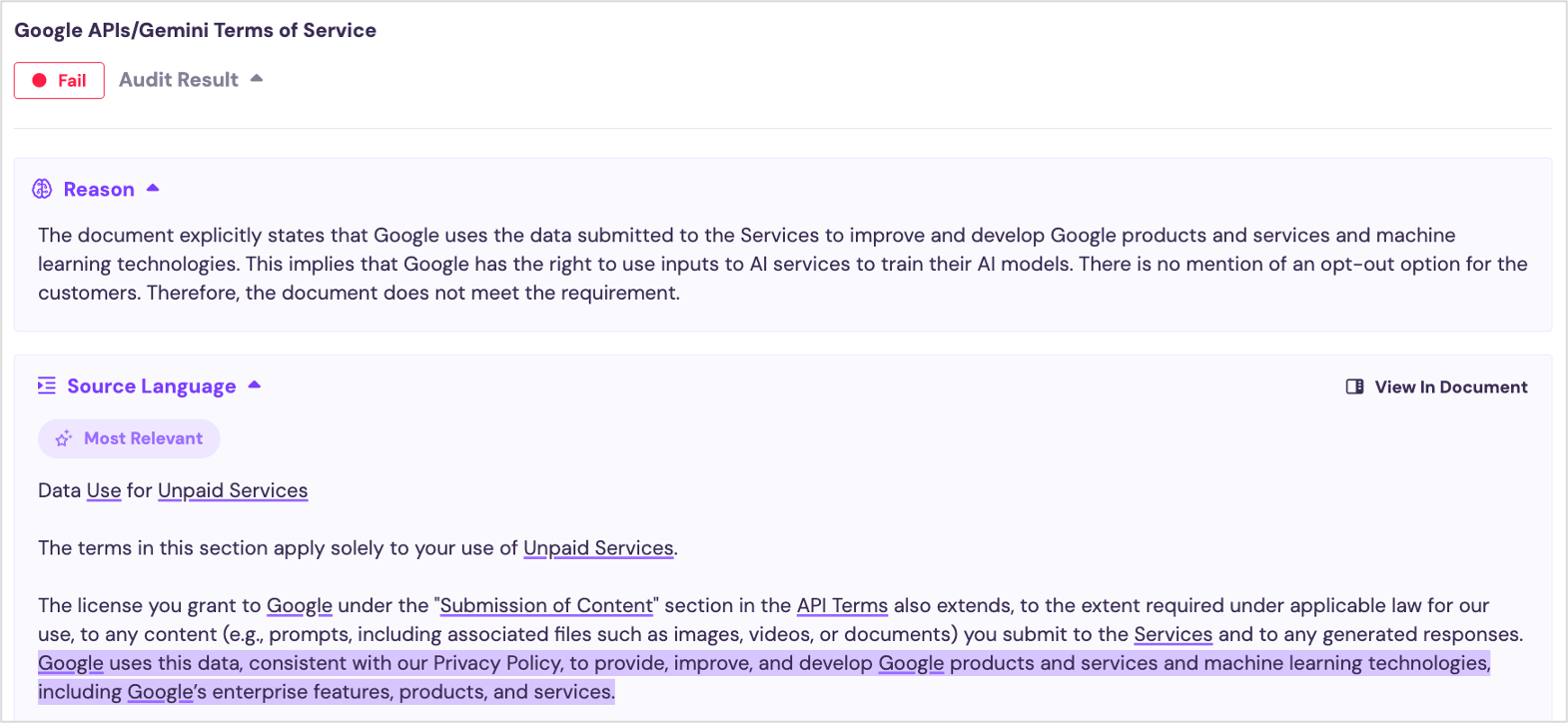
This input usage, however, is only for the use of Unpaid Services. Our analysis is regarding the commercial use of AI services, which means we are concerned with Paid Services. Using the Screens platform, we can quickly audit the result by drilling in further to look for nearby text in the document. Just above the cited clause, we see that Google Gemini uses different terms for Paid Services:

This distinction between Paid Services and Unpaid Services is new in the Gemini Terms of Service as of May 2nd, 2024, and we think this is the right direction. It puts Gemini more in line with OpenAI and Anthropic. For our purposes, this passes the standard.
Cohere’s contract doesn’t talk about enhancing machine learning services or training AI models, but their contract says they can use customer data to “improve and enhance” their services. Again, interpretations vary, and that’s pretty typical cloud vendor language. But in a gen-AI contract, it’s broader than we’d like. We don’t know whether Cohere uses customer data to train AI models, but as shown below, the contract terms plausibly allow it:


The Screens platform listed the various contracts’ definitions of “customer data.” For Cohere, that includes anything you enter into the API or SaaS services, such as prompts, documents, images, etc.
If we’re building systems on top of an AI platform, we look for explicit usage rights and restrictions.
OpenAI provides a good example of this approach:
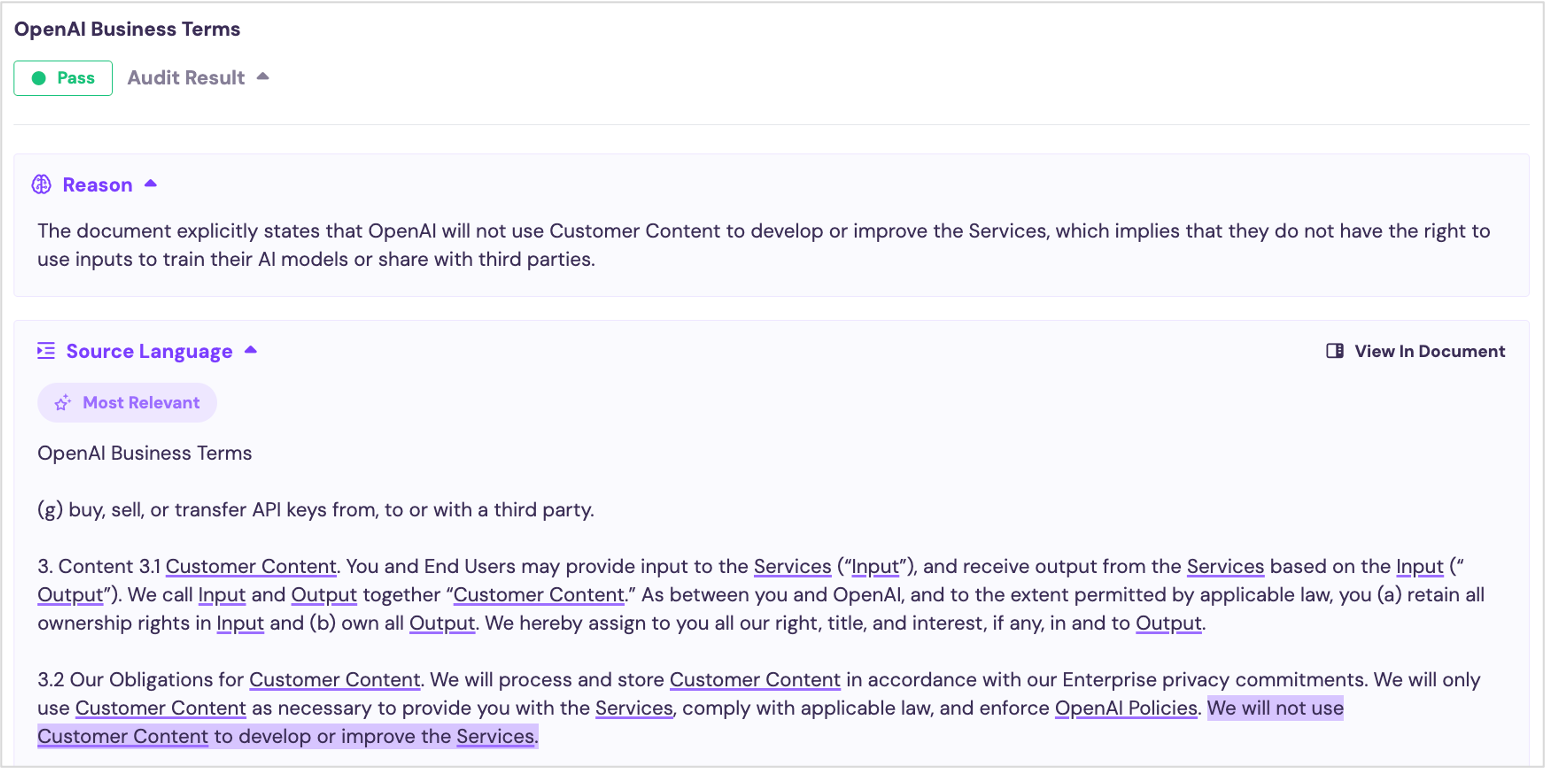
This is what we want to see. OpenAI promises not to use customer data to improve its services. And they define this to mean both inputs and outputs of the services.
Screens’ contract is even more explicit:

Contract drafters can’t always offer this sort of simplicity. Business relations can be complex. But where possible, simple promises and simple language remove friction. And that’s particularly important with machine learning systems and their potential use of training data.
A contract can also pass this data use standard if it offers an opt-out. An opt-out is unlikely to be a customer’s preference (it’s easy to forget to do it), but we still find this satisfactory. Albeit, it means you’ve got to actually read your contracts … carefully.
Here is an example from AWS:
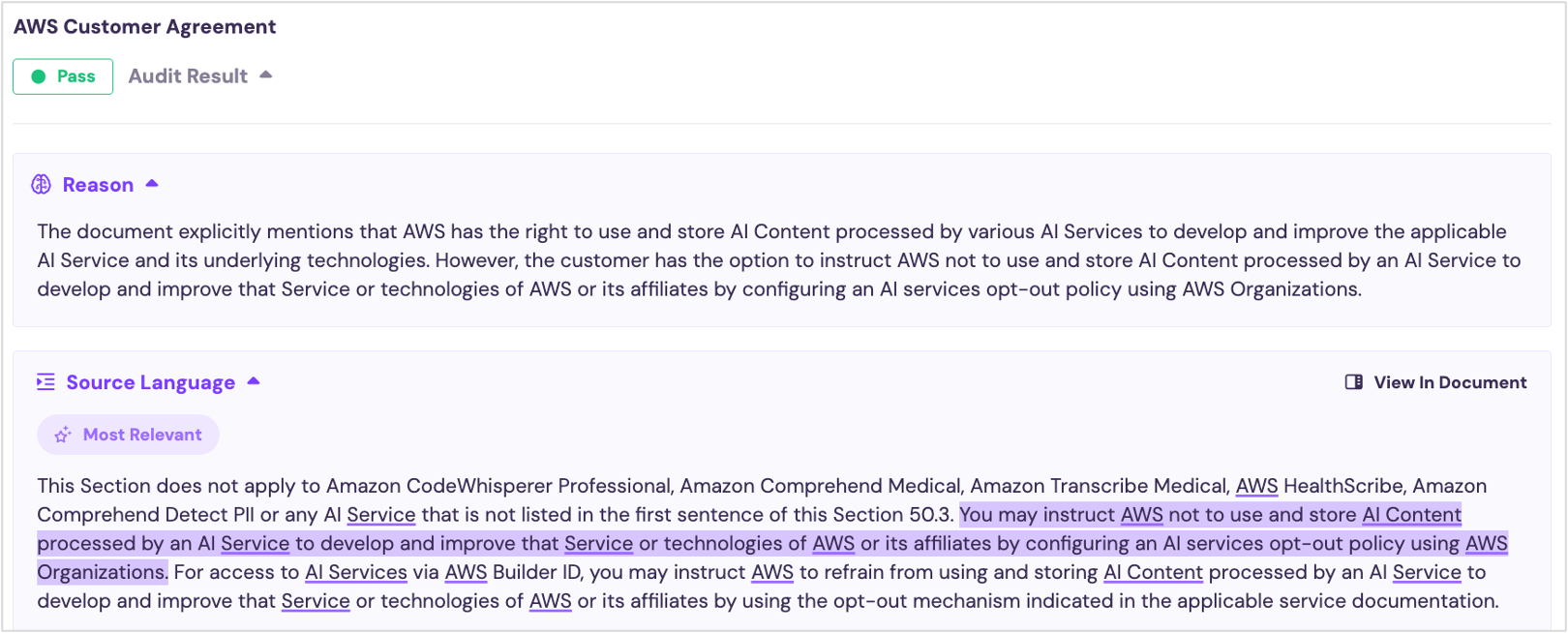
This appears deep within the AWS Service Terms (37,000 tokens deep if you include the parent customer agreement).
2. Confidentiality
We also asked Screens to review nondisclosure terms related to inputs and outputs. Here is how we frame the standard:
The vendor must agree not to disclose input data or outputs to third parties without the customer’s written consent.
This standard goes beyond promises about how the provider will use data. It asks if the provider promises to keep data confidential. That’s meant to protect company secrets—particularly trade secrets, which need reasonable protections, like NDAs, to maintain their status.
Below are our three non-compliant contracts:

Google Gemini and AWS both have clauses protecting their own confidential information but do not reciprocate that protection for customers. For example, the Screens platform flagged this clause from AWS as potentially relevant to the standard, but not sufficient for the standard to pass:

The AWS contract restricts disclosure of AWS Confidential Information, but this isn’t the kind mutual confidentiality provision that we often see in SaaS/cloud provider contracts.
Here is an example from Open AI of what we want to see:

They specifically include Customer Content in the Confidential Information definition: the definition of information the recipient won’t disclose (Customer Content includes Inputs and Outputs of the AI service, per OpenAI’s definition). We’d prefer that the clause say Customer Content is the Customer’s Confidential Information, not OpenAI’s. But that’s a relatively safe assumption. This is another example of simple language and reasonable clarity removing friction in relationships between parties.
A final note about information protection. We directed Screens to look at nondisclosure, not protection of private information. They’re connected but not the same, and the latter is outside the scope of this article.
3. Other standards
The screen we prepared explores a number of other areas of interest including:
- Ownership of fine-tuned models
- “Ownership” of input and output data and content
Before looking at those IP provisions, it’s worth discussing two much misunderstood features of intellectual property.
First, you can’t actually own input or output data—or any data—at least in any meaningful way. Data is information. And patents protect inventions, not information, while copyrights protect expression—words, notes, images, etc.—not the ideas or information expressed. At best, you might have a weak form of copyright protecting the compilation of your input data, output data, or fine-tuning data; or alternatively, some related limited IP right. But those rights probably won’t keep your provider or anyone else from exploiting that data: mining it, reproducing parts of it, etc. You might also have trade secret rights, as we’ve seen. But they also provide limited rights rather than the sort of control we imagine when we say, “we own our data.”
Second, the provider might agree that you own the content in outputs, but that also might not mean much. Generative AI outputs could include more than data. They could include software, images, and text, any of which could get copyright protection in normal circumstances. But current U.S. law doesn’t allow copyrights in machine-created works. (Some jurisdictions, like Britain and China, seem to have more flexible laws, yet even there, ownership of purely machine-created work remains uncertain.) If a human contributes to a machine-created work, copyright might apply (though the law isn’t certain).However, the provider almost certainly won’t contribute any human effort to your output-creation. Rather, it’s just its AI doing the work. So the provider may have no IP whatsoever to give you.
None of this analysis means you should ignore IP. The concerns don’t apply to IP in content within your inputs and finetuning data. By “content,” we mean software, images, text, and other works that aren’t just data. You could own the content you provide; thus, LLM provider acknowledgment of your ownership would be valuable. And even with data or content in outputs, LLM provider acknowledgment of your ownership has some value. It’s worth pursuing. Just recognize that those IP terms might not mean much and thus should not distract your focus from the usage rights terms discussed near the start of this article.
The other issues we had Screens check are:
- Usage rights for fine-tuned models
- Non-compete provisions
- Non-solicitation provisions
- Limits on liability
For the most part, the contracts we analyzed got perfect scores on these remaining standards. We’ll highlight one issue you might want to explore more.
Cohere can share fine-tuning with third parties.


The graphic to the right is how Cohere defines fine-tuning data. Suffice to say, if you are using Cohere for fine-tuning models with sensitive input data, be careful.
Why review contracts you can’t negotiate?
We’re often asked why reviewing vendor contracts is important if you don’t have any power to negotiate.
A major cloud provider or leading foundational LLM vendor might keep its hosted click-through terms as provider-favorable as possible. When these companies have waitlists or limited capacity due to GPU constraints, the last thing they’ll do is negotiate their standard terms with small customers.
But negotiation isn’t the only reason to understand your contract. You need to know how bad it is so you can decide whether to sign. And you’re better off if you know the limits of your legal protections, so you know how to protect customers’ data and your own—e.g., by avoiding certain services or opting out of certain grants of rights.
Currently, the most cost-effective way to accomplish this is by running contracts through a screen (an expert-designed contract playbook powered by gen-AI). If you’d like to replicate this analysis on your own, customize the screen to your liking, create your own screen from scratch, screen more publicly hosted terms of service, screen your private negotiated contracts, and more, you can get started at no cost here.