
How should legal teams get started with data? Here’s a prescription, along with a #RealTalk diagnostic.
In Post 066, I shared that law firm and law department leaders often ask me how to get started with data analytics. I also shared that I usually respond by asking about their most important strategic objectives.
For today’s post, I will play doctor and take a cut at a framework to serve as a prescriptive roadmap. The above graphic is the result. It visualizes a practical framework to think structurally about high-value applications of data.
To Design a Value Proposition for Data Analytics, Start with Clear Thinking Around Needs
As with any new idea, tool, service or product, the key to designing a successful value proposition is to think deeply about the needs of the intended end-user.
Decision support, when applied to sufficiently high-stakes contexts in both the business of law (e.g. new business models for legal service delivery) and practice of law (e.g. litigation finance), likely offers the highest probability of generating material economic returns or a strategic leap forward for the sponsoring organization. Of course, identifying the decision opportunity and shaping the analytics approach requires a high threshold of domain knowledge as well as technical expertise across both data engineering and data science competencies — hence the need for a multi-disciplinary team.
Execution support. That said, for the time being, the most widespread data efforts in the legal market probably still focus on fairly familiar products around business intelligence, operational dashboards and financial reporting. While there is plenty of opportunity here for useful deployment of data-informed decisions and actions, the pace of innovation here is unlikely to hit a drastic inflection point due to the heavy burdens around process improvement and change management for data handling, on an organization-by-organization basis.
Persuasion. Broadly in the world, the art of storytelling has gotten almost as much adoration as data science in recent years, but this is one area that hasn’t gotten much traction in legal. (Let’s see if 2019 brings us a bit more ✨ sparkle.)
Common Complaints, Pain Points & 😱💀 Horror Stories 👻🤡
As with many other topics about new and evolving capabilities, dialogue about data in the legal industry can be confusing and contradictory. There is a material level of hype (Big 📊 Data 🤯 disrupting 🤯 Big ⚖️ Law!!) – paired per usual with the requisite cynicism and skepticism (LOL 😆 lawyers can’t speak data 😖😰🙄).
In the abstract, I 💖 data. Full stop. 😍
Out in the real world, however, my adoration for data has many disclaimers, disclosures, and exceptions — particularly when it comes to the legal industry. In this section, I address a few of my misgivings about the current state of data usage in the legal vertical, drawing not only on my own experiences but also the most common complaints I hear in my travels.
1. We Have the Data Sets We Deserve (but Not Always the Ones We Need 🦇)
This is often how it starts. Because most legal organizations are in possession of some data assets, and because data-informed or data-driven methods are all the rage these days, many organizations embark on directionless and costly exercises to squeeze insights from the data they already have.

Conversations that begin this way are hugely concerning to me. What I hear in this exchange is “sure, I’d love to see something interesting or cool because it sounds like it’s free.” That’s not a cost benefit equation with a high probability of a happy ending, for two reasons:
- Overvaluing existing data assets without regard to data quality or sufficiency (more on this a bit)
- Underestimating the cost and effort required to extract business value from those assets
On the business of law side, both data sufficiency and data condition are material concerns. A point worth noting here is that much of the existing business data in the legal industry oriented around cost to the buyer: most of the readily available data sets across law firms and law departments tend to come from time-and-billing systems and provide the history of transactions, essentially as accounting events. Of course, these data sets often suffer from material quality issues that require time and money to resolve.
Very few law firms and law departments have comparable depth or volume of data oriented around value delivered. In other words, there are precious few readily available and reliable systems of record that capture the history of legal events through which the service provider created and delivered value to the buyer of legal services. On a per-organization basis, more practice management or experience database solutions are emerging to help create this record, and in very few cases correlate those events directly to billing data. However, in 2018, such efforts are relatively nascent, particularly relative to the time-and-billing systems that have served law firms as their primary mission-critical system for many decades.
In such instances, the upside potential of the project often has a hard ceiling — yet issues with data condition can mount, not just in hard dollar expense but also time lag and overall drag on the organization. Particularly in projects without a sharp focus on the end-goal, those costs and subsequent adverse impact on the organization can be significant: not least, the potential for change fatigue and mounting resistance to future endeavors involving data.
In short, designing an analytics program at scale represents a material investment of organizational resources. To secure sufficient ROI on such an effort, analytics must meet a higher bar than simply being interesting — analytics must be useful. And the overall utility and value proposition of the data effort should, whenever possible, be articulated at the outset, not while a costly effort is in flight.
2. Mostly Neglected Everywhere: Assessments of Data Sufficiency
My favorite question format on the GMAT is unique to the exam: data sufficiency. (Yes, it is weirdly 🤓🤓🤓 to admit I have a favorite question type on standardized tests. For inquiring minds, I 💕 logic games on the LSAT and analogies on the SAT.)
I provide an example below:

For everyone whose eyes glazed over, that’s OK. Data sufficiency enjoys a flavor of notoriety even among the b-school crowd. The question doesn’t directly test for quantitative problem-solving aptitude; the provided problem (in the example above, the ratio of full-time to part-time employees in Division X and Company Z) is usually asinine and beside the point.
Rather, data sufficiency questions test aptitude for metacognition: how to 🤔 think about 🤔 thinking. Correctly answering a data sufficiency question is at its core an exercise in logical reasoning, in addition to a test of content understanding of number properties and statistics. More precisely put, this question format demands rigorous and structured thinking about the underlying method of problem-solving, and most importantly the ability to correctly identify the factual inputs required to generate insights relevant to the problems or objectives at hand.
This represents hard work for our brains that feels unnatural, because the exercise of evaluating data sufficiency requires that we focus on the white space — something beyond reacting to or dealing with the facts and numbers that are right in front of us. This question asks us to think categorically and descriptively about whether we might need facts and numbers that are not readily available.
This is a very specific type of thinking that we don’t often practice in the legal industry. We ought to.
3. Data Sets Have Origin Stories, but We Often Ignore Them
Most data sets don’t simply appear out of thin air via immaculate conception. In some way shape or form, most data sets are generated by people.
Just watched a little boy gleefully press the red button for about five minutes. #datadriven pic.twitter.com/LUhgIidVuU
— Michelle Broderick (@MichelleBee) May 2, 2018
In most brick-and-mortar businesses and product-heavy sectors, sensors do much of the work around collecting and gathering data, often unobtrusively in the background. The same is true for high-tech platform plays where data on user behavior turns out to be the core product to be monetized.
That said, the legal services market is still a services-first category, and our industry still relies heavily on manual data inputs. As a result, busy and stressed people are clicking buttons or filling out fields to generate many of our data sets, particularly in intra-organizational initiatives in knowledge management and practice data maintenance. This type of data work demands accuracy and precision, which are two areas where humans tend not to excel. These tasks also tend to comprise the more tedious and soul-crushing components of anyone’s job: data upkeep/maintenance is usually the “one last thing” on the checklist or to do list before quitting time, and on most days, these tasks probably don’t get done. 🤷♀️
Particularly because we tend to function in environments that produce low-fidelity data, understanding the means and mechanics of data collection is a critical prerequisite to defensible analysis and interpretation. Too many teams working with data in law firms and law departments function as database (or spreadsheet) administrators, overwhelmed with the mechanics of data collection and cleaning without a serious attempt to engage with the content of the data sets — i.e. what the data says and what it all might mean.
The Root Cause Diagnostic: New & Different Methods Require More & Different Skills (but Not in One New Super-Lawyer)
Out in the real world, using data to actually solve real problems is much 😓 harder and more 😩 effortful than a day of GMAT prep, and the requisite skills are both valuable and rare. The ability to identify the needed inputs and assess the best method of obtaining them are skills we don’t associate directly with data analysis. These upstream competencies in fact-finding and fact collection are skills taught in research, investigation and intelligence work — across academic, enforcement, military and corporate traditions.
In practice, work to assess and achieve data sufficiency tends to look both non-linear and messy, because it is. In addition to a firm grasp on the mechanics of research design, the team must bring to bear some depth of domain knowledge (content understanding of the specific facts and data points relevant to the problem at hand) and environmental familiarity (the ability to navigate the available universe of sources and to assess each information source for reliability). Lastly, this type of work benefits from a few specific attributes: intellectual curiosity, resourcefulness, and tenacity.
Often, generating original and useful insights requires multiple cycles of hypothetical reasoning followed by factual investigation. Formulating smart and specific questions to explore requires creative and open-ended thinking rooted in meaningful understanding of the problem, and actually going out to verify what is happening out in the real world requires a willingness to engage in legwork.
All this is a tall order. In 2011, McKinsey predicted that “by 2018, the U.S. alone could face a shortage of 140,000 to 190,000 people with deep analytical skills as well as 1.5 million managers and analysts with the know-how to use the analysis of big data to make effective decisions.” See “Big Data: The Next Frontier for Innovation, Competition, and Productivity,” McKinsey Global Institute, June 2011. Fast forward to this year: big data and analytics has topped the skill shortage list for the 4th year running in the annual Harvey Nash/KPMG CIO Survey, and two-thirds of IT leaders say this shortage is “preventing them from keeping up with the pace of change.” See “Big Data Skills Shortages – and How to Work Around Them,” Computer Weekly, June 2018.
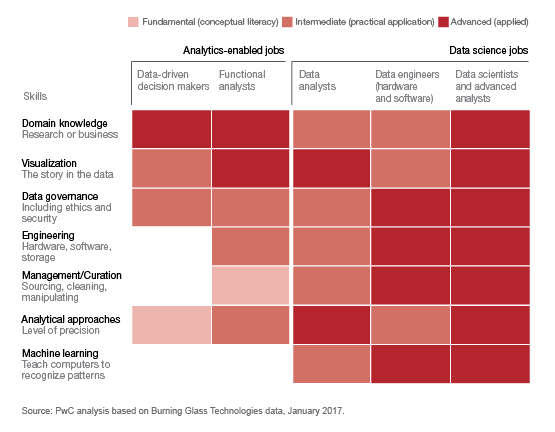
A 2017 analysis by PwC echoed McKinsey’s 2011 prediction, noting that the overall talent need will be “mostly for business people with analytics skills, not just analysts.” See “What’s Next for the Data Science and Analytics Job Market?,” PwC Research and Insights, January 2017.
The grid above sets forth their recommended skill inventory mapped to jobs across two categories: analytics-enabled business roles and more technical data science roles. This is an instructive model for legal practitioners and legal educators alike: increasingly, there is a need to rethink the boundaries of the legal practitioner role, either as “data-driven (legal) decision makers” or “data-enabled (legal) analysts.”
I particularly favor this PwC model because it sidesteps a couple of familiar traps. Once in a while, Law Twitter revives the debate over whether lawyers should learn to code (strong opinions abound). I’ve never been fond of how this question is framed. Firstly, I’m not sure it’s helpful to debate whether all lawyers should learn to code. Secondly, I think the question lacks nuance and specificity about what level of conceptual literacy or practical prowess “learning to code” would or should comprise. (As for my two cents on the “learn to code” debate, I agree 🙌 with Jason Barnwell’s hilarious tweet below.)
Legal professionals generally investing 10 hours to understand what one can do with code is a great idea. But let's not call that learning to code. That's like fighting a traffic ticket and saying you have learned to law.
— Jason Barnwell (@smuckwell) September 2, 2018
What the PwC skill grid accomplishes in one visual is to remind us that the full complement of analytics skills modern organizations need must be spread across several jobs. Analytics is a team sport. What’s more, the PwC grid also communicates very effectively that each distinct role demands a differing mix of skills.

Modern law, too, is increasingly a team sport. Legal teams are particularly challenged to field a high-performing team that brings together the full complement of necessary skills, for several reasons. In the current state, the vertical not only has a skills shortage but no real pipeline strategy to attract high-caliber analytics talent. See Post 066 (talent shortage as structural barrier to innovation). That talent shortage is exacerbated by the extreme fragmentation in the industry. See Post 051 (key graphic). Indeed, as a mental exercise, I’d be willing to lay 10-to-1 odds that there simply aren’t 200 qualified candidates to lead serious data analytics initiatives at each of the Am Law 200 firms.
{kind=link}
The industry relies on pockets of brilliance for thought leadership (Dan Katz of Chicago-Kent & LexPredict and Evan Parker of LawyerMetrix come to mind). However, advancing analytics-enabled thinking at scale will require a much larger talent pool and/or a more creative market-making solution to help scale the limited supply of talent to a broader swath of demand.
A New Hope, Always: the Legal Industry Isn’t Actually That Far Behind the Curve
Before I close, though, let’s take a slightly different look at the state of data analytics in legal — because tech products represent one pathway to scaling the promise of analytics on a one-to-many model. See Susskind, The End of Lawyers? (2010) (introducing one-to-one and one-to-many terminology). Certainly as of late, more and more legal tech and content players are focused on data applications with the potential to arm legal practitioners and business stakeholders to make better legal and business decisions faster: these efforts currently coalesce around natural language processing, from extraction to categorization and reasoning. Some of these component technologies are already baked into mainstream products in legal research and document intelligence categories:

Many of these products are still likely enjoying success in early markets, but both categories seem poised on the cusp of penetrating mainstream markets. The Research category demonstrates an unsurprising level of consolidation given the longstanding oligarchy of incumbent content publishers. The document subcategories are still fairly crowded, particularly in the diligence engine subcategory: whether a clear winner will emerge, it is too early to say.
One last noteworthy point is that the legal vertical may represent a fairly optimal lab environment to test frontier technologies in the more advanced NLP subcategories like machine translation. In that sense, the perpetual notion that the legal industry is perennially behind everyone else may be a bit fatalistic — and signals in the marketplace suggest that there is likely sufficient interest from both capital and the buying market to drive those experiments forward, particularly in the upmarket segment of Big Law:
- Eigen Technologies, which works closely with both Linklaters and Hogan Lovells, raised a $17.5m Series A round in June of this year, with Goldman Sachs as lead investor. See “Eigen Technologies Raises £13m,” finextra.com, June 11, 2018.
- Luminance raised a $10m Series A round in late 2017 with Slaughter and May on its investor roster. See “Slaughters Ramps Up Luminance Investment in $10m Round,” The Lawyer, November 29, 2017.
So, is the legal industry really a decade behind everyone else in how we use and consume data to make decisions? While it probably feels that way to many market participants, I take a slightly more positive view. The advance guard is certainly charging forward. As for most of us in the middle of the pack, I’m here to tell you that many of our frustrations and complaints are commonly heard outside the legal industry.
What I do think we need to improve might be our attitudes: more willingness to invest in attracting new technical talent and more attention to developing the talent we already have by way of education and training would probably go a long way.
What’s next? See Introducing contributor Dan Rodriguez (076)